It's pretty normal for you to want to have a stable system.
What happens though, when parts of your system depend upon other 3rd party systems? What happens, when your cloud provider lumps you with a network that sometimes decides to disable itself, where the only fix is to give them even more money?
Answer: Design and build with resilience in mind.
Designing For Known Failures
We can start by simply digging into our experience pool to unearth some of the obstacles we may have previously encountered - there's nothing new under the sun and a problem you've previously had is likely to be a problem you will experience again. Are any of your historic solutions applicable in your new, or current system?
Architect away from single points of failure when designing your system - ensure the ability to provide redundancy for each of our system's components and also the ability to easily scale out.
When designing your system, you can consider the Bulkhead Design Pattern:
Bulkheads
Bulkheads are used to seal off parts of boats and ships to prevent sinking.

As a pattern in Microservice Architecture, it's a way of sealing off failure and avoid cascading failure (one failure leading to many more failures in the same part, and other parts of a system).
The core concept here, is to separate out your components in a way where one failure doesn't impact the whole system and ensure degraded functionality when part of the system goes down.
Degraded functionality is a term to express that a piece of functionality may gracefully disappear or be partially complete.
Okay, so...
You can start by thinking about how you might want to divide your system up.
The whole Microservice Architecture ethos lends itself to this pattern quite naturally - small, isolated services, each with their own data stores that can only be accessed via that service.
To take that further, you can consider a service's criticality - you don't want a high volume, low critical service bombarding a message queue and hindering a highly critical and perhaps low volume service from functioning correctly.
In that scenario, you'd provide your critical service dedicated resources, like it's own message queue to stop it's functionality being impacted by less important stuff. This can be applied to any shared resource, like a database which could be split into several databases as needed.
Microservices suit horizontal scaling well - essentially running multiple instances of a service in order to meet demand.
The use of Load Balancers will stop any incoming calls being directed to a misbehaving instance of a service, isolating that service from use until it returns to functioning order.
We can also reject incoming calls to a service when that service is at maximum capacity - this is called Load Shedding.
Finally, we can make sure we use the Circuit Breaker Pattern on all synchronous 3rd party (upstream) calls - we'll dive into what that means momentarily.
Embracing Failure
Things go wrong. That upstream service might not be accepting calls right now. Your DNS service might be trying to take today off as annual leave.
Whilst we now have a pattern to feed into our architecture, there are three patterns that work hand-in-hand within our components to help mitigate complete system meltdown: Timeouts, Retries and Circuit Breakers.
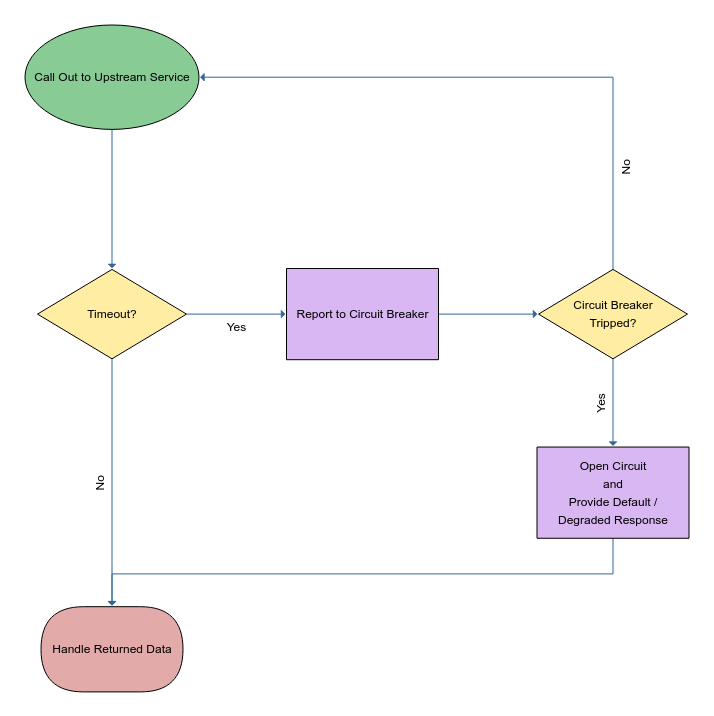
Timeouts
If you spent any time interacting with the world-wide web, you've come across a timeout error before. It means that your browser has become fed up with waiting for data from the website you're trying to access.
You can define how long your services wait for outgoing calls to complete and then what to do in the event that a call does take too long. This means you can avoid cascading failures by handling timeouts with default, or degraded functionality. Timeouts alone only reduces the risk of a service running out of threads to work on though - it'll still be accepting and trying to handle incoming requests.
Retries
Timeouts are typically used in conjunction with a Retry strategy - which are ideal for combating those transient faults, where there might be a momentary loss of connectivity. Usually, you'll attempt to retry a call either straight away, or after a pre-determined amount of time. After a small number of retries, you should hook back into your timeout handling logic for default or degraded functionality.
Please make sure that you log all retry attempts, it'll make your life much easier when you perform any tracing.
Circuit Breakers
Finally, you can tie both Timeouts and Retries with the Circuit Breaker pattern to not only eliminate cascading failure but also avoid having your services run out of threads.
A circuit breaker monitors your outgoing calls for any timeouts or errors and trips when a defined failure threshold is reached.
When tripped, your circuit breaker is 'open' and will return an error, or a default response on behalf of the upstream service without actually calling that upstream service - wave goodbye to further timeouts and hello to thread availability.
After some time, the circuit breaker will go into a 'half-open' state and attempt to reconnect with the upstream service. If successful, the circuit breaker will 'close' up and everything will return to functioning as designed. If unsuccessful, the circuit breaker will remain 'open' and attempt to open up a little later.
You can write your own circuit breaker using the many open source examples out there - make sure it's thread safe and at least has a configurable failure threshold and open state duration. There are 3rd party libraries kicking around, Resilience4J is one I've come across for Java developers.
It's important to log your circuit breaker state changes for tracing too.
Degrading and Defaulting Functionality
If we're going to fail, we should fail as fast as we can, to at least remain responsive to our users. Even though we can't always avoid sending an error message back to our caller, we should attempt providing degraded or default functionality first.
We've already explained that degrading functionality is a term to express that a piece of functionality may gracefully disappear or be partially complete. The circuit breaker pattern allows for this partial shift in functionality.
An example of degraded functionality is when an advertisement service is unable to return data to a website. After a circuit breaker trips, the degraded functionality could mean that adverts aren't displayed until the advertisement service starts working again.
Default functionality is what you provide when all else fails. Normally this will be some data from a cache or, if we must, an error message.
Fin
Thank you for reading this post, I know it's a long one for me.
Hopefully, you've found it useful - if you have any thoughts or opinions on the content in this post, please do reach out to me in the comments section below.