Let's ask the most important question anyone worth knowing can be asked: How many chicken nuggets can I eat in 3 minutes?
Now, I'm a sucker for a box of nuggs - especially after a night of playing pool in the pub! Let's say I'm going to keep trying to beat the world record, one attempt directly after another, until I beat it.
So I'm timing myself and keeping my records but anyone who wants to know my best attempt so far will have to wait until I've finished stuffing my face for 3 minutes flat until they get my response...this is where Command and Query Responsibility Segregation (CQRS) comes in.
Imagine you've got a service that's receiving so much data that it's unable to serve requests for information efficiently - much like my face stuffing. Horizontal scaling will help with the problem somewhat - if there's enough people stuffing their faces, maybe there'll be less nuggs to consume per person and more opportunity to answer questions.
A better solution is to split up the workload - we do microservices, remember! We will have one service, with it's own database, for consuming data - handling all the inserting, updating and deleting of data via commands (e.g. "Eat one more nugget")... And another service with it's own database for handling the incoming requests for information.
The only remaining challenge here is to keep the two databases synchronised. Most modern databases support some form of replication, or event publishing upon data change. These features can be utilised to achieve our goal.
In the nugget scenario, this would be me smashing nuggs and recording each world record attempt onto a clipboard. Every time I complete a run I show my clipboard to my friend, who adds my latest statistic changes to his clipboard. My friend answers any questions my adoring fans have.
Taking a break from the fast food eating maniac I can become after half a pint...
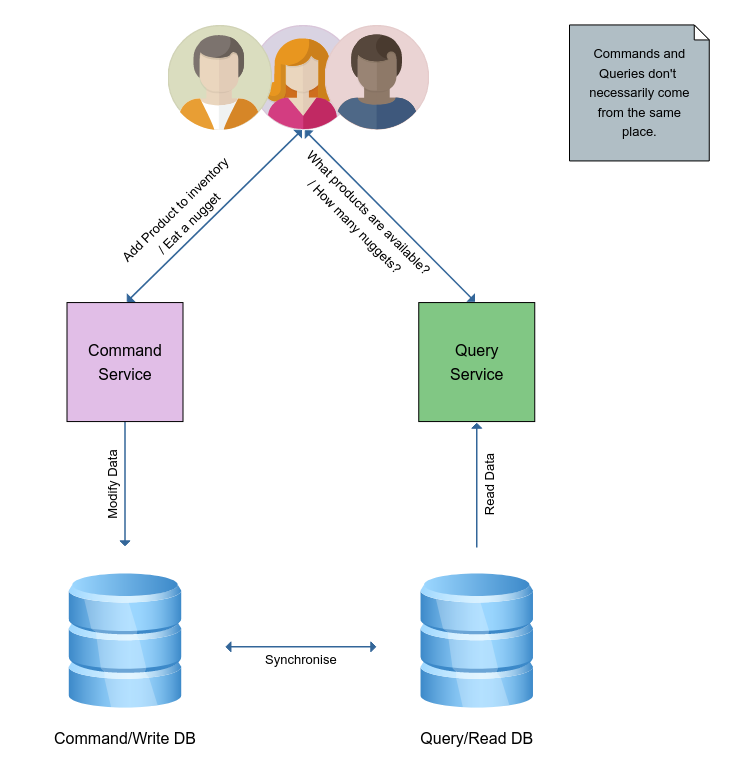
The separation of concerns allows us to apply intensive validation and translation on incoming data commands and have that data written to a schema optimised for having data written to it. On the other side of the coin, we can serve a materialised view for read operations - streamlining our service reading from that database by avoiding any complex queries.
We are also granted more granularity when scaling our services too. If the incoming data set is of mammoth proportions, we can have more "data writer" services running. If the query rate is high, then we can scale up the "data reader" service. The scaling of either side of the overall service won't have an impact on the opposing microservice due to the use of separate data stores.
It's not all sunshine and barbecue sauce though. Implementing CQRS might add some complexity to your application design. If message queues are used, you'll have to tackle the handling of failed or duplicate messages between your databases.
You also need to be aware that your read, or query ready data will be a little stale compared to the freshly cooked info in the write, or command database...this eventual consistency might only involve a a few minutes, or even just a few seconds but it will impact how "real-time" your data is for the users of your service.
Done
So there we have it - CQRS isn't great for a man on a diet but is good for heightened isolation of your microservices (think bulkhead pattern) and segregating read and write DB operations means performance gains for less-than-real-time data.